There's a version of precision agriculture that treats yield maps and soil tests as parallel inputs that each independently justify prescriptions. Yield data generates one set of management zones; soil test data generates another; and the grower applies whichever one their agronomist brought to the table this year. We don't think that's the right way to use these data sources.
Yield maps and soil samples are complementary, not interchangeable. Each answers a different question. Yield maps describe outcomes — where the crop performed well or poorly, and how consistently that performance pattern held over multiple years. Soil samples describe inputs — the nutrient levels, pH, CEC, and organic matter that constrain or enable crop performance. Using them together — specifically, using yield stability to define zone boundaries and soil sample data to validate and characterize those zones — produces management zones that are more defensible, more durable, and more useful for prescription development than either data source alone.
What yield maps tell you (and what they don't)
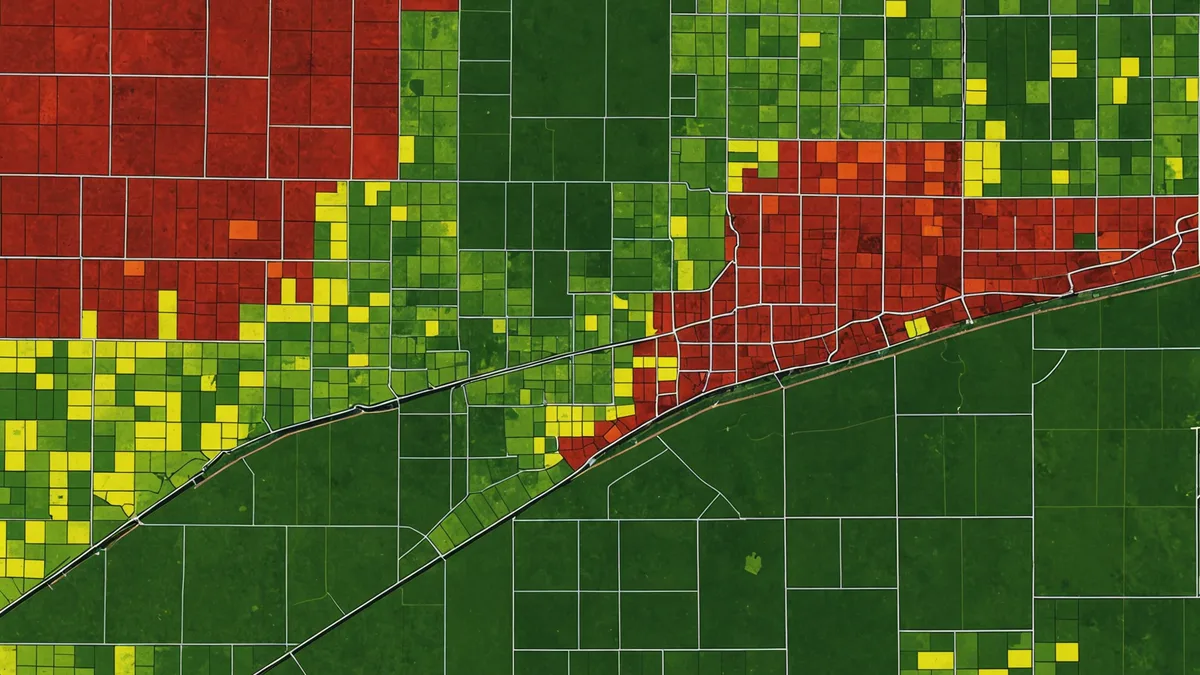
A single-year yield map contains a mix of useful information and noise. Weather, pest pressure, equipment issues, planting conditions, and in-field management decisions during that season all show up in the yield variation you're looking at. A wet year depresses yields in poorly drained zones. A dry year penalizes coarse-textured sandy areas that lose soil water quickly. These year-specific effects are real, but they're not what you want to define permanent management zones around.
The signal you're looking for in yield data is stability — zones that consistently rank high, medium, or low across multiple seasons with different weather patterns. A zone that yields in the bottom quartile in wet years and dry years and normal years is telling you something about the underlying soil constraints, not just about last year's weather. That kind of stability is what justifies differential management.
For zone construction, we use a minimum of three years of cleaned yield data, ideally five or more. More years gives you better weather-averaging and makes it easier to separate stable constraints from year-specific effects. We clean the data before analysis — removing edge passes, header height transition zones, and speed-related outliers — because uncleaned harvest data has substantial spatial noise that will generate spurious zone boundaries if you run clustering directly on raw monitor output.
The cleaned, multi-year yield composite serves as the structural backbone for zone boundaries. It tells us where the field's performance gradient is. What it doesn't tell us is why that gradient exists or what nutrient inputs to assign to each zone.
What soil samples tell you (and what they don't)
Soil test data tells you about current nutrient availability, pH, organic matter, and CEC — the building blocks of what a crop can access from the soil. Taken at the right depth (0-6 inches for P and K, 0-8 inches for pH, 0-24 inches for nitrate profiling), soil test values are accurate representations of what's in the ground at the time of sampling.
The limitation of soil test data for zone construction is that a single sampling event is a snapshot. P and K build up over decades of differential application and removal. pH gradients reflect both parent material and lime application history. These properties don't change dramatically from year to year in a managed agricultural system, which makes them good characterizers of existing zones — but they're less useful for drawing zone boundaries from scratch because they don't capture the yield response dimension at all.
A field where every zone has adequate P and K levels (say, P index at 30-40 ppm, K at 180-200 ppm across the board) won't show meaningful soil test differences between management zones even if the field has a 15 bu/acre consistent yield spread driven by drainage. The soil test can't explain the yield difference in that field. The yield map can identify it, and soil EC or SSURGO texture data can explain it.
Conversely, a field that's been under uniform N-P-K applications for 20 years without any zone-based management may have developed significant soil test gradients that closely track the zones that yield data suggests. High-yielding zones remove more P and K in grain, so they often have lower soil test values despite identical application rates. In that field, the soil test data and yield data will point to similar zones — but you're still getting more information by looking at both than by treating either as sufficient.
The integration workflow
The workflow we use in Soilynx to integrate yield and soil data follows a defined sequence. Yield history drives zone boundaries; soil test data drives zone characterization and prescription targets.
Step one: build yield stability zones from 3-5 years of cleaned corn yield data (or soybeans, though corn yield maps tend to have higher point density from the monitor). Use a clustering algorithm — k-means works well for most Midwestern field geometries — to produce 3-4 stability zones. Validate zone boundaries visually against your soil EC map and SSURGO data to confirm they're tracking real soil features rather than random year-to-year variation.
Step two: overlay existing soil sample points on the yield zones. For each zone, calculate the distribution of each key nutrient (P, K, pH, OM) from sample points that fall within that zone. This step tells you whether your yield zones correspond to meaningful nutrient differences.
If a zone shows both consistently low yield AND consistently low P (below 15 ppm on Bray-1), that zone is probably responsive to P application. You have two lines of evidence pointing the same direction. If a zone shows consistently low yield but adequate to high P across all sample points, the yield limitation is coming from something else — drainage, compaction, pH, micronutrient, or an agronomic constraint outside the nutrient realm. Trying to address that low yield with P application is unlikely to move the needle.
Step three: use the zone nutrient distributions to calibrate prescription rates. ISU Extension soil fertility recommendations for Iowa corn and soybeans provide the framework — P and K application rates based on soil test levels and yield goal. We use those recommendations as the agronomic baseline and let the zone analysis direct which recommendation tier applies where.
A specific scenario: the split-response field
Consider a 240-acre field in Benton County, Iowa — a mix of Muscatine silty clay loam (the high ground, consistent 195-210 bu/acre corn) and Tama silt loam in the lower slope positions (165-175 bu/acre), with a poorly drained Sawmill silty clay complex in one corner (120-145 bu/acre depending on the year). Three yield stability zones emerge cleanly from 5 years of harvest data.
Soil sample data from 2.5-acre grid sampling (collected 3 years prior) shows the following: the Muscatine high-ground zone has P at 22 ppm and K at 195 ppm, both in the medium-high range. The Tama mid-slope zone has P at 14 ppm and K at 165 ppm — marginal. The Sawmill low corner has P at 19 ppm and K at 148 ppm.
Without yield data, you'd write a flat P and K prescription with a modest bump for the marginal Tama zone. With yield stability data, you know the Tama mid-slope zone has room to respond to nutrient management — it's not drainage-limited like the Sawmill corner — so the case for nutrient investment there is stronger. The Sawmill corner has adequate P but low K, but since that zone's yield ceiling is driven primarily by drainage, K application above maintenance level is unlikely to return value until the drainage constraint is addressed.
The yield map doesn't write the prescription. The soil test doesn't write the prescription. The combination tells you where to invest and where not to — and why.
When the two datasets disagree
Sometimes yield data and soil test data point in opposite directions. A zone that yields consistently high but shows depleted P is common in intensively managed fields — high removal rates from high yields over many seasons deplete the bank. That zone deserves nutrient investment to maintain performance, but you wouldn't know that from yield data alone — the yield map looks great, so you might deprioritize it.
A zone that yields consistently low despite high soil test values is more puzzling. This is where the combined dataset prompts the right diagnostic question: if nutrients aren't limiting and yield is still low, what is? Compaction, drainage, soil pH extremes, nematode pressure, and tile line gaps are all candidates. At minimum, the data combination tells you where NOT to spend money on fertilizer, which is itself a useful prescription.
We're not saying that integrating yield maps and soil tests answers every agronomic question on a field — it doesn't. But it answers more questions than either source alone, and the zones it produces hold up across multiple seasons because they're grounded in both performance history and soil chemistry, not just one snapshot from either.